

关于 1.Stable Diffusion到底是什么?
本章文章将介绍stable diffusion是什么 发展历程等
平台
浏览 183 , 收录与 2025-06-14 12:32:11
产品介绍
Stable Diffusion
原作者: Runway、CompVis、Stability AI
原始码库: github.com/Stability-AI/generative-models
程式语言: Python
类型: 文本到图像生成模型
网站: stability.ai/stable-image
许可协议: CreativeML Open RAIL-M
首次发布: 2022年8月22日
Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词指导下产生图生图的转变。
它是一种潜在扩散模型,由慕尼黑大学的CompVis研究团体开发的各种生成性人工神经网络之一。
它是由初创公司StabilityAI、CompVis与Runway合作开发,并得到EleutherAI和LAION的支持。
截至2022年10月,StabilityAI筹集了1.01亿美元的资金。
Stable Diffusion的源代码和模型权重已分别公开发布在GitHub和Hugging Face,可以在大多数配备有适度GPU的电脑硬件上运行。而以前的专有文生图模型(如DALL-E和Midjourney)只能通过云计算服务访问。
技术架构
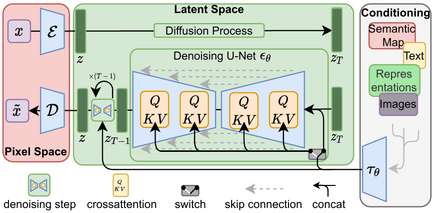
Stable Diffusion是一种扩散模型(diffusion model)的变体,叫做“潜在扩散模型”(latent diffusion model; LDM)。扩散模型是在2015年推出的,其目的是消除对训练图像的连续应用高斯噪声,可以将其视为一系列去噪自编码器。Stable Diffusion由3个部分组成:变分自编码器(VAE)、U-Net和一个文本编码器。与其学习去噪图像数据(在“像素空间”中),而是训练VAE将图像转换为低维潜在空间。添加和去除高斯噪声的过程被应用于这个潜在表示,然后将最终的去噪输出解码到像素空间中。在前向扩散过程中,高斯噪声被迭代地应用于压缩的潜在表征。每个去噪步骤都由一个包含ResNet骨干的U-Net架构完成,通过从前向扩散往反方向去噪而获得潜在表征。最后,VAE解码器通过将表征转换回像素空间来生成输出图像。研究人员指出,降低训练和生成的计算要求是LDM的一个优势。
去噪步骤可以以文本串、图像或一些其他数据为条件。调节数据的编码通过交叉注意机制(cross-attention mechanism)暴露给去噪U-Net的架构。为了对文本进行调节,一个预训练的固定CLIP ViT-L/14文本编码器被用来将提示词转化为嵌入空间。
用法
Stable Diffusion模型支持通过使用提示词来产生新的图像,描述要包含或省略的元素,以及重新绘制现有的图像,其中包含提示词中描述的新元素(该过程通常被称为“指导性图像合成”(guided image synthesis)通过使用模型的扩散去噪机制(diffusion-denoising mechanism)。 此外,该模型还允许通过提示词在现有的图中进内联补绘制和外补绘制来部分更改,当与支持这种功能的用户界面使用时,其中存在许多不同的开源软件。
Stable Diffusion建议在10GB以上的显存下运行, 但是显存较少的用户可以选择以float16的精度加载权重,而不是默认的float32,以降低显存使用率。
文生图
Stable Diffusion中的文生图采样脚本,称为"txt2img",接受一个提示词,以及包括采样器(sampling type),图像尺寸,和随机种子的各种选项参数,并根据模型对提示的解释生成一个图像文件。 生成的图像带有不可见的数字水印标签,以允许用户识别由Stable Diffusion生成的图像,尽管如果图像被调整大小或旋转,该水印将失去其有效性。 Stable Diffusion模型是在由512×512分辨率图像组成的数据集上训练出来的,这意味着txt2img生成图像的最佳配置也是以512×512的分辨率生成的,偏离这个大小会导致生成输出质量差。 Stable Diffusion 2.0版本后来引入了以768×768分辨率图像生成的能力
每一个txt2img的生成过程都会涉及到一个影响到生成图像的随机种子;用户可以选择随机化种子以探索不同生成结果,或者使用相同的种子来获得与之前生成的图像相同的结果。 用户还可以调整采样迭代步数(inference steps);较高的值需要较长的运行时间,但较小的值可能会导致视觉缺陷。另一个可配置的选项,即无分类指导比例值,允许用户调整提示词的相关性(classifier-free guidance scale value);更具实验性或创造性的用例可以选择较低的值,而旨在获得更具体输出的用例可以使用较高的值
反向提示词(negative prompt)是包含在Stable Diffusion的一些用户界面软件中的一个功能(包括StabilityAI自己的“Dreamstudio”云端软件即服务模式订阅制服务),它允许用户指定模型在图像生成过程中应该避免的提示,适用于由于用户提供的普通提示词,或者由于模型最初的训练,造成图像输出中出现不良的图像特征,例如畸形手脚。 与使用强调符(emphasis marker)相比,使用反向提示词在降低生成不良的图像的频率方面具有高度统计显著的效果;强调符是另一种为提示的部分增加权重的方法,被一些Stable Diffusion的开源实现所利用,在关键词中加入括号以增加或减少强调。
图生图
Stable Diffusion包括另一个取样脚本,称为"img2img",它接受一个提示词、现有图像的文件路径和0.0到1.0之间的去噪强度,并在原始图像的基础上产生一个新的图像,该图像也具有提示词中提供的元素;去噪强度表示添加到输出图像的噪声量,值越大,图像变化越多,但在语义上可能与提供的提示不一致。 图像升频是img2img的一个潜在用例,除此之外。
2022年11月24日发布的Stable Diffusion 2.0版本包含一个深度引导模型,称为"depth2img",该模型推断所提供的输入图像的深度,并根据提示词和深度信息生成新图像,在新图像中保持原始图像的连贯性和深度。
内补绘制与外补绘制
Stable Diffusion模型的许多不同用户界面软件提供了通过img2img进行图生图的其他用例。内补绘制(inpainting)由用户提供的蒙版描绘的现有图像的一部分,根据所提供的提示词,用新生成的内容填充蒙版的空间。
随着Stable Diffusion 2.0版本的发布,StabilityAI同时创建了一个专门针对内补绘制用例的专用模型。相反,外补绘制(outpainting)将图像扩展到其原始尺寸之外,用根据所提供的提示词生成的内容来填补以前的空白空间。
是否可以商用
与DALL-E等模型不同,Stable Diffusion提供其源代码以及预训练的权重。其许可证禁止某些使用案例,包括犯罪,诽谤,骚扰,人肉搜索,“剥削…未成年人”,提供医疗建议,自动创建法律义务,伪造法律证据,以及“基于…社会行为或…个人或人格特征…或受法律保护的特征或类别而歧视或伤害个人或群体”。 用户拥有其生成的图像的权利,并可自由地将其用于商业用途。
模型训练
Stable Diffusion是在LAION-5B的图片和标题对上训练的,LAION-5B是一个公开的数据集,源自从网络上抓取的公用抓取数据。该数据集由LAION创建,LAION是一家德国非营利组织,接受StabilityAI的资助。该模型最初是在LAION-5B的一个大子集上训练的,最后几轮训练是在“LAION-Aesthetics v2 5+”上进行的,这是一个由6亿张带标题的图片组成的子集,人工智能预测人类在被要求对这些图片的喜欢程度打分时至少会给5/10打分。这个最终的子集也排除了低分辨率的图像和被人工智能识别为带有水印的图像。 对该模型的训练数据进行的第三方分析发现,在从所使用的原始更广泛的数据集中抽取的1200万张图片的较小子集中,大约47%的图像样本量来自100个不同的网站,其中Pinterest占8.5%子集,其次是WordPress,Blogspot,Flickr,DeviantArt和维基共享资源等网站。
该模型是在亚马孙云计算服务上使用256个NVIDIA A100 GPU训练,共花费15万个GPU小时,成本为60万美元。
为了纠正模型初始训练的局限性,终端用户可以选择实施额外的训练,以微调生成输出以匹配更具体的使用情况。有三种方法可以让用户对Stable Diffusion模型权重存档点进行微调:
“嵌入”(Embedding)可以从用户提供的一些图像被训练出来,并允许模型在提示词中使用嵌入的名称时生成视觉上相似的图像。嵌入是基于2022年特拉维夫大学的研究人员在英伟达的支持下开发的“文本倒置”(Textual Inversion)概念,其中模型的文本编码器使用的特定标记的矢量表示与新的伪词相关系。嵌入可以用来减少原始模型中的偏差,或模仿风格。
“超网络”(Hypernetwork)是NovelAI软件开发员Kurumuz在2021年创造的一种技术,最初用于调节文本生成的Transformer模型,它能让Stable Diffusion派生的文生图模型模仿各种特定艺术家的风格,无论原始模型能否识别此艺术家,通过在较大的神经网络中的不同点应用一个预训练的小神经网络。超网络将文生图或图生图结果导向特定方向,例如加上艺术风格,当与一个较大的神经网络结合使用时。它通过查找重要的关键区域来处理图像(例:眼睛,头发),然后在二级潜在空间中修补这些区域。超网络的一个缺点是它们的准确性相对较低,也有时会产生不可预知的结果。因此,超网络适用于加上视觉风格或清理人体瑕疵。
DreamBooth是一个深度学习模型,由Google Research和波士顿大学的研究人员于2022年开发,可以微调模型以产生与指定主题相关的输出图像。
相关产品

Sketchar
一款用于艺术创作和学习的增强现实绘画应用,配有AR助手和数字画布。
Scribble Diffusion AI
AI驱动的软件,将草图转变为精细图像。

DrawnBy.AI
一个从狗狗照片生成艺术杰作的人工智能平台。

nano banana
超快速的 AI 图像编辑器,具有精确的局部控制和多图像融合。
Picture to Drawing
AI工具瞬间将照片转换为艺术绘画。
Dreamer: AI Art Generator
用于根据文本生成AI艺术的移动应用,使用稳定扩散v2。

Doodlify
AI 工具瞬间将照片转化为色彩缤纷的涂鸦艺术。

AI Photo Art
利用AI将照片转变为多种艺术风格。
Artistry AI
利用AI的绘图应用,能够将涂鸦转变为艺术佳作,并支持图像放大。

Illustro – AI Illustration Generator
AI 插图生成器和 AI 插图编辑器,用于现代矢量插图。

Sketcho.io
Sketcho.io 将草图转化为AI生成的图像,用于艺术创作和创意灵感。

AI Image Wizard
通过写作提示生成和编辑图像的AI应用。

Midjourney Prompt Helper
一个为 Midjourney 生成提示的插件,提高绘画效率并激发创意。

Picas
Picas使用人工智能将照片转换为著名艺术效果的艺术作品。

pixeldraw007
一个由 Scribble Diffusion 和其他 AI 模型驱动的用于图像生成的创意工具。